System Administrator Guide¶
Introduction¶
This guide, designed for a System Administrator, covers installation and setup of the Web Curator Tool.
For information on using the Web Curator Tool, see the Web Curator Tool Quick Start Guide and the Web Curator Tool User Manual.
Contents of this document¶
Following this introduction, the Web Curator Tool System Administrator Guide includes the following sections:
- Getting Started - covers prerequisites, supported platforms, other platforms, and optional prerequisites for using the Web Curator Tool.
- Setting up the WCT database - procedures for setup using Oracle, MySQL and PostgreSQL.
- Setting up the WCT Application - procedures for deploying WCT, includes configuration options and troubleshooting.
- Setting up Heritrix 3 - procedures for building and running the Heritrix 3 web crawler to intergrate with WCT, includes configuration options and troubleshooting.
- Appendix A: Creating a truststore and importing a certificate
- Appendix B: Example application profile overrides
Getting Started¶
The following section explains how to get the Web Curator Tool up and running.
Prerequisites¶
The following are required to successfully install and run the Web Curator Tool:
- Java 1.8 JDK or above (64bit recommended)
- A database server (supported versions in parenthesis)
- Oracle (11g, 12c)
- PostgreSQL (8.4.9, 9.6.11)
- MySQL (5.0.95 or newer)
- MariaDB (10.0.36)
Other versions of the required products may be compatible with the Web Curator Tool but they have not been tested. Due to the products use of Hibernate for database persistence other database platforms should work, if the product is rebuilt with the correct database dialect. However only Postgesql, Oracle, MySQL and MariaDB have been tested.
Supported platforms¶
The following platforms have been used during the development of the Web Curator Tool:
- Red Hat Linux EL3.
- Ubuntu GNU/Linux 16.04, 18.04 LTS
- Mint GNU/Linux 19.1 LTS
- Windows 7 Ultimate, Windows 10
Other platforms¶
The following platforms were used during the Development of the Web Curator tool but are not explicitly supported:
- Sun Solaris 10
Optional prerequisites¶
The following prerequisites are optional:
- LDAP compliant directory (for external authentication)
- Apache Maven 3+ (required to build from source).
- Gradle 5.6 (required to build from source; other versions may also work).
- Git (can be used to clone the project source from Github)
Setting up the WCT database¶
Setup using Oracle¶
This guide assumes you have installed and configured Oracle prior to setting up the WCT database and schema.
Setup two schemas: one called DB_WCT that owns the tables and one called USR_WCT that the application uses to query the tables. The USR_WCT schema should have limited rights. You can use the following SQL script to do this:
db/latest/setup/wct-create-oracle.sql
Run the following SQL scripts under the DB_WCT user or SYSTEM account:
db/latest/sql/wct-schema-oracle.sql db/latest/sql/wct-schema-grants.sql db/latest/sql/wct-indexes-oracle.sql db/latest/sql/wct-bootstrap-oracle.sql db/latest/sql/wct-qa-data-oracle.sql
The wct-qa-data-oracle.sql script will generate QA indicator template data for the new QA module for each agency, and should be run once all agencies have been added to WCT. Note that if the script is re-run, it will clear out any existing template data.
A password strategy should be defined for the system, and the db_wct & usr_wct passwords should be changed in the scripts and application property files to conform to this strategy. To encourage this, the passwords in the supplied database creation script are set to ‘password’.
The bootstrap user script creates a User with a name of ‘bootstrap’ and a password of ‘password’. Use this account to login to the application once it is up and running. You can use the bootstrap account to create other users and agencies. Once you have setup valid users, it is best to disable the bootstrap user for security reasons.
Setup using PostgreSQL¶
This guide assumes you have installed and configured PostgreSQL prior to setting up the WCT database and schema.
Create the database, using the following script:
db/latest/setup/wct-create-postgres.sql
Run the following SQL scripts under the DB_WCT user or SYSTEM account:
db/latest/sql/wct-schema-postgres.sql db/latest/sql/wct-schema-grants-postgres.sql db/latest/sql/wct-indexes-postgres.sql db/latest/sql/wct-bootstrap-postgres.sql db/latest/sql/wct-qa-data-postgres.sql
The wct-qa-data-postgres.sql script will generate QA indicator template data for the new QA module for each agency, and should be run once all agencies have been added to WCT. Note that if the script is re-run, it will clear out any existing template data.
A password strategy should be defined for the system, and the db_wct & usr_wct passwords should be changed in the scripts and application property files to conform to this strategy. To encourage this, the passwords in the supplied database creation script are set to ‘password’.
The bootstrap user script creates a User with a name of ‘bootstrap’ and a password of ‘password’. Use this account to login to the application once it is up and running. You can use the bootstrap account to create other users and agencies. Once you have setup valid users, it is best to disable the bootstrap user for security reasons.
Setup using MySQL¶
This guide assumes you have installed and configured MySQL prior to setting up the WCT database and schema.
Create the database, using the following script:
db/latest/setup/wct-create-mysql.sql
Run the following SQL scripts under the DB_WCT user or SYSTEM account:
db/latest/sql/wct-schema-mysql.sql db/latest/sql/wct-schema-grants-mysql.sql db/latest/sql/wct-indexes-mysql.sql db/latest/sql/wct-bootstrap-mysql.sql db/latest/sql/wct-qa-data-mysql.sql
The wct-qa-data-mysql.sql script will generate QA indicator template data for the new QA module for each agency, and should be run once all agencies have been added to WCT. Note that if the script is re-run, it will clear out any existing template data.
A password strategy should be defined for the system, and the db_wct & usr_wct passwords should be changed in the scripts and application property files to conform to this strategy. To encourage this, the passwords in the supplied database creation script are set to ‘password’.
The bootstrap user script creates a User with a name of ‘bootstrap’ and a password of ‘password’. Use this account to login to the application once it is up and running. You can use the bootstrap account to create other users and agencies. Once you have setup valid users, it is best to disable the bootstrap user for security reasons.
Setting up the WCT Application¶
Downloading WCT¶
The binaries for the WCT components can be downloaded from the releases page in the Github repository.
Building WCT¶
Alternatively, WCT can be built from source.
To build WCT:
Make sure you have installed and configured Java 1.8 JDK, Maven 3+, Gradle 4.4+ and Git.
Clone the code repository from Github using Git:
git clone https://github.com/WebCuratorTool/webcurator.git
Navigate to the webcurator-legacy-lib-dependencies/ sub-directory, and run either of the following scripts (depending on your operating system) to install the required legacy dependencies:
- install_maven_dependencies.bat - install_maven_dependencies.sh
Navigate back to the root webcurator directory, and build the project using Gradle:
gradle clean install
Once built, the binary for each component will be located under the following paths:
- webcurator-webapp/build/libs/webcurator-webapp.war - webcurator-store/build/libs/webcurator-store.war - webcurator-harvest-agent-h3/build/libs/webcurator-harvest-agent-h3.jar
Deploying WCT¶
There are three major components to the deployment of the Web Curator Tool:
- Webapp (webcurator-webapp.war)
- Digital Asset Store (webcurator-store.war).
- Harvest Agent (harvest-agent-h3.jar)
Each of these three components must be deployed for the Web Curator Tool to be fully functional and more than one harvest agent can be deployed if necessary. Each Harvest Agent is capable of carrying out harvest actions. The more harvest agents are deployed the more harvesting can be done concurrently. The harvest agents and digital asset store can reside on any machine within the network, as they use REST over HTTP to communicate with each other.
To deploy WCT:
Make sure you have installed and configured Java 1.8 JDK.
Make sure you have installed and configured your database of choice, and that it is now running.
Place the webapp, store and harvest-agent binaries in the location you wish to run them from. An additional logs directory will be created here on startup.
Start the WCT files using a standard Java command:
java -jar webcurator-webapp.war java -jar webcurator-store.war java -jar harvest-agent-h3.jar
These commands can be run in the foreground for testing, but it is recommended to run them in the background, using a tool like Unix’s nohup command. Note that you will likely need to configure WCT to suit your environment, see Configuring WCT properties.
To stop any WCT component, simply terminate the running process, or if running in the foreground, simply use Ctrl+c.
Before logging into WCT, ensuring all components are shutdown, modify the configuration files in the following steps.
Additional command line properties¶
Additional properties can be passed to the Java Virtual Machine (JVM) for WCT on the command line. For instance, the maximum allowed memory a WCT component can use:
java -Xmx512m -jar webcurator-webapp.war
Memory
Increased memory allocation for Webapp and Store may be required if performance issues are experienced with the harvest visualization feature from v3.1 onwards. This can be dependent on the size of harvests and whether all the WCT components and Heritrix are running on a single server.
Configuring WCT properties¶
Inside each component binary, there is an application.properties file which contains configuration properties for WCT:
- webcurator-webapp.war/WEB-INF/classes/application.properties
- webcurator-store.war/WEB-INF/classes/application.properties
- harvest-agent-h3.jar/BOOT-INF/classes/application.properties
Modify the properties in application.properties, and restart the corresponding WCT component for them to take effect.
The properties can also be overridden, using a local Spring application profile
(e.g. application-local.properties, application-local+mysql.properties). This provides flexibility for
configuring WCT in different environments and settings. The profile filename must use the structure
application-<profile name> .properties. By default, webcurator-webapp.war, contains several example
profiles that can be used and customized for the Webapp:
- application-local+h2.properties
- application-local+mysql.properties
- application-local+oracle.properties
- application-local+postgres.properties
Also, see Appendix B for an extended Spring Profile override example
To change the profile loaded with a WCT component at runtime, either
Inside the WCT component binary, open the application.properties file for editing. Set the spring.profiles.active property to the profile name to be loaded, then save application.properties:
E.g. - spring.profiles.active=local+postgres - spring.profiles.active=dev+mysql+ldap
Ensure a corresponding profile with the correct filename is located in the same folder:
E.g. - webcurator-webapp.war/WEB-INF/classes/application-local+postgres.properties - webcurator-webapp.war/WEB-INF/classes/application-dev+mysql+ldap.properties
Or, set the profile when running the WCT component. The corresponding profile can be located inside the WCT binary or outside it, in the same directory:
java -jar webcurator-webapp.war --spring.profiles.active=local+mysql
Note: If you do not wish to edit the binaries, you can actually override any application.properties file inside the binaries, by creating a file of the same name (e.g. ‘application.properties’, ‘application-local+mysql.properties’) inside the directory where you run the java command. You only need to add the variables that you wish to override. Spring Boot will pick up the other variables from the namesake file inside the binary. This goes for all three components.
Configure TLS/SSL access¶
Since you will be sending credentials over potentially untrusted networks when you login, it is wise to configure the Webapp to use TLS/SSL. To do so you need to create a keystore containing the certificate for your server, using a tool such Java’s keytool. (The process of acquiring and importing a CA-signed certificate is outside of the scope of this document.) Then add the following properties to the relevant application properties file:
# The format used for the keystore. It could be set to JKS in case it is a JKS file
server.ssl.key-store-type=PKCS12
# The path to the keystore containing the certificate
server.ssl.key-store=wct.p12
# The password used to generate the certificate
server.ssl.key-store-password=password
# The alias mapped to the certificate
server.ssl.key-alias=wct
# forces ssl
server.ssl.enabled=true
server.port=8043
Note that key-store is a filepath relative to the working directory of the java command used to run the application. The key-alias should match the alias you used when adding the certificate to the keystore (with keytool’s -alias argument). You should also update the harvestCoordinatorNotifier.baseUrl and the webapp.baseUrl properties in the application.properties of the Harvest Agents and the Store (respectively) to reflect the changed server.port and the ‘https’ URL scheme of Webapp.
TODO: This will not work for self-signed certificates. Additional configuration of Harvest Agents and Store is required.
Configure the Database Connection¶
Inside webcurator-webapp.war, open the properties profile that corresponds to the database type you are using:
E.g. - webcurator-webapp.war/WEB-INF/classes/application-local+mysql.properties - webcurator-webapp.war/WEB-INF/classes/application-local+oracle.properties - webcurator-webapp.war/WEB-INF/classes/application-local+postgres.properties
Adjust the following properties to match your database installation:
# Database properties databaseType=postgres schema.name=db_wct schema.url=jdbc:postgresql://localhost:5432/Dwct schema.user=usr_wct schema.password=password schema.driver=org.postgresql.Driver schema.dialect=org.hibernate.dialect.PostgreSQL82Dialect schema.query=select 1+1 schema.maxIdle=2 schema.maxActive=4
If the default WCT database scripts have been used to setup the database then the name and user, properties should not need to be changed. You are of course strongly encouraged to change the default password. Verify the url and dialect properties match the location and version of your database.
Update this properties file inside webcurator-webapp.war with any changes.
Load the Spring profile for your database configuration, either by setting the spring.profiles.active property inside the application.properties file, or through the commandline:
java -jar webcurator-webapp.war --spring.profiles.active=local+postgres
Configure LDAP Authentication¶
If you wish to use an external Directory for Authentication, then WCT can be configured to allow this. Unencrypted authentication can be done very simply with your directory by modifying the relevant properties file inside webcurator-webapp.war.
Please note - the Directory must support LDAP.
Open the application.properties file inside webcurator-webapp.war, or a local Spring application profile if one is being used.
Locate the # LDAP properties section, or add it if using a local Spring application profile:
# LDAP properties ldap.enabled=false ldap.url.build=ldap://yourldapserver.domain.com:389/ ldap.usr.search.base=ou=people ldap.usr.search.filter=(uid={0}) ldap.group.search.base=ou=groups ldap.group.search.filter=(member={0}) ldap.contextsource.root=dc=com ldap.contextsource.manager.dn= ldap.contextsource.manager.password=
Set ldap.enabled to true to enable LDAP Authentication:
ldap.enabled=true
Initially set the following two parameters:
- ldap.url.build, which defines the URL for the directory. This is normally something like ldap://mydirectory.natlib.co.nz:<port-number>
- ldap.contextsource.manager.dn. This allows the Directory DN to be defined. For example, if a user logs in with the username “gordonp” the Directory will be queried using the distinguished name of “cn=gordonp, ou=wct, o=global”. So the user must exist within the global organisation and the wct organisation unit.
Set any other required parameters, and remove any unneeded default values.
Configure LDAP Authentication (Encrypted using TLS or SSL)¶
If you want all credentials passed to the Directory server to be protected then the ldap traffic should be encrypted using TLS or SSL.
The scheme prefix ldaps is required in the ldap.url property:
ldap.url=ldaps://yourldaphost.domain.com:389
If using TLS or SSL then you must configure the application to allow secure communication with your Directory by adding the following properties to the application.profile of the Webapp:
server.ssl.trust-store=/var/wctcore/ssl/wct.ts server.ssl.trust-store-password=password server.ssl.client-auth=need
This points Spring Boot to a Truststore that contains the public key for you directory. If your directory utilises a correctly signed certificate, you may not need this, as the default truststore provided by Java contains all the major root certificates. However if you directory uses a self-signed certificate then you will need to export the public key of that certificate and import it into your truststore (i.e. /var/wctcore/ssl/wct.ts). Alternatively you can import the self-signed certificate into the default Java truststore.
For details on how to create a truststore and import a certificate, see Appendix A: Creating a truststore and importing a certificate.
Configure the Digital Asset Store (DAS)¶
Inside webcurator-store.war, open the application.properties file for editing:
webcurator-store.war/WEB-INF/classes/application.properties
Set the server.port property to an open port on the server that the Digital Asset Store (DAS) will run on:
server.port=8082
Set the Base Directory of the DAS to a valid location on the server. Also make sure the directory or shared folder has enough free disk space:
# The base directory of the Digital Asset Store arc.store.dir=/usr/local/wct/store
Set the base URL (scheme, host, port and context) connection details for the Webapp:
# the base service url of Webapp webapp.baseUrl=http://localhost:8080/wct
Update the application.properties file inside webcurator-store.war with any change.
Alternatively, set the above parameters in your DAS local Spring application profile, and override the default values in application.properties.
Open the application.properties file inside webcurator-webapp.war, or the local Spring application profile if one is being used.
Set the base URL (scheme, host and port) connection details for the DAS:
# the base service url of the digital asset store digitalAssetStore.baseUrl=http://localhost:8082
Set the directory for transferring assets to the Digital Asset Store. Make sure the directory is a valid location on the server and has enough free disk space:
# the folder for transferring assets to the Digital Asset Store digitalAssetStoreServer.uploadedFilesDir=/usr/local/wct/store/uploadedFiles/
Update the application.properties file inside webcurator-webapp.war with any change.
Configure a Heritrix 3 - Harvest Agent¶
Inside harvest-agent-h3.jar, open the application.properties file for editing:
harvest-agent-h3.jar\BOOT-INF\classes\application.properties
Set the server.port property to an open port on the server that the Harvest Agent will run on:
server.port=8083
Set the Base Directory of the Harvest Agent to a valid location on the server:
harvestAgent.baseHarvestDirectory=/usr/local/wct/harvest-agent
Note, the
harvestAgent.baseHarvestDirectorypath cannot match the Heritrix 3 jobs directory. This will cause a conflict within the H3 Harvest Agent.Set the base URL (scheme, host, port and context) connection details for the Webapp:
# the base service url of Webapp harvestCoordinatorNotifier.baseUrl=http://localhost:8080/wct
Set the base URL (scheme, host, and port) connection details for the DAS:
digitalAssetStore.baseUrl=http://localhost:8082
If the Harvest Agent will be running on a different server to the DAS, then set the file upload mode to stream:
# 1) copy: when Harvest Agent and Store Component are deployed on the same machine; # 2) stream: when Harvest Agent and Store Component are distributed deployed on different machines; digitalAssetStore.fileUploadMode=copy
Make sure the following parameters match the Heritrix 3 instance details:
# The H3 instance scheme. h3Wrapper.scheme=https # The H3 instance host. h3Wrapper.host=localhost # The H3 instance port. h3Wrapper.port=8443 # The H3 instance full path and filename for the keystore file. h3Wrapper.keyStoreFile='' # The H3 instance password for the keyStore file h3Wrapper.keyStorePassword='' # The H3 instance userName. h3Wrapper.userName=admin # The H3 instance password. h3Wrapper.password=admin
Update the application.properties file inside harvest-agent-h3.jar with any change.
Alternatively, set the above parameters in your Harvest Agent local Spring application profile, and override the default values in application.properties.
In addition to setting the Harvest Agent parameters, you may also want to change the default Heritrix v3 profile that is shipped with the WCT. See the Default profile section.
Logon to WCT¶
Once you have started up the Web Curator Tool logon to the application using the ‘bootstrap’ user with the default password of ‘password’. This account has enough privilege to create other Agencies and Users within the system. Once you have configured valid WCT users and tested their login’s work, you should disable the bootstrap user.
The URL to access WCT will be similar to the one displayed below:
Where ‘localhost’ can be replaced with your server, and 8080 with the configured Webapp port.
Troubleshooting setup¶
See the following table to troubleshoot Web Curator Tool setup.
| Problem | Possible solution |
|---|---|
| Database connection failure | Check that the WCT Webapp data source is defined correctly in the application.properties file or your local Spring application profile. This profile must be loaded via the spring.profiles.active property in application.properties or the command line. Also check that the server can communicate with this host on the specified port. |
| LDAP configuration failure | If problems occur with getting TLS working with ldap, then switch on the SSL debug mode by adding the following to the Java start command for Webapp. The debug will display on the console. -Djavax.net.debug=ssl,handshake |
| Communication failure on Heartbeat | Validate that the distributed agents have the correctly defined central host and can communicate with this host over HTTP. |
| Failure on storing the harvest to the store | Validate that the Digital Asset Store has been configured with the correct directory settings and has write access to the specified directory. |
| Failure on Harvest attempt (or Harvest action appears to hang) | 2006-07-04 07:51:31,640 ERROR [http-8080-Processor24] agent.HarvestAgentHeritrix (HarvestAgentHeritrix.java:88) - Failed to initiate harvest for 262147 : Failed to create the job profile C:tmpharvest-agent262147order.xml. org.webcurator.core.harvester.agent .exception.HarvestAgentException: Failed to create the job profile C:tmpharvest-agent262147order.xml. at org.webcurator.core.harvester.agent .HarvestAgentHeritrix.createProfile (HarvestAgentHeritrix.java:542) at org.webcurator.core.harvester.agent .HarvestAgentHeritrix.initiateHarvest (HarvestAgentHeritrix.java:79) at org.webcurator.core.harvester.agent .HarvestAgentSOAPService.initiateHarvest (HarvestAgentSOAPService.java:37) If any error similar to the one above occurs, it is usually related to an incomplete harvest taking place. If this occurs you will need to remove the Target Instance sub-directory from the deployed baseHarvestDirectory as specified in the application-local.properties file. In the example above you would delete the directory called c:\tmp\harvest-agent\262147. |
| QA Process does not appear to run or QA indicators are not generated | Check that QA indicators have been defined in the Management tab of WCT. The wct-qa-data-[mysql|oracle|postgres].sql scripts, located in webcurator-db, have been provided to generate initial values for the QA indicators. |
Configuration Options¶
This section describes additional options for configuring the Web Curator Tool.
Webapp Configuration - application.properties¶
The following are common configuration options for the Webapp adjusted via the application.properties file.
Application Context
The server.servlet.contextPath can be configured to run the Webapp from a custom application context. This context can be seen at the end of the WCT URL, http://localhost:8080/wct. Remember to also adjust the Webapp baseUrl configuration for the DAS and each Harvest Agent
server.servlet.contextPath=/wct
Mail Server
The mailServer is responsible for communicating with an SMTP mail server for sending email notifications
mail.protocol=SMTP mailServer.smtp.host=yourhost.yourdomain.com mail.smtp.port=25
In Tray Manager
The inTrayManager is responsible for informing users of Tasks or Notification messages. This uses the mailServer to send email. Also defined here is the sender of the automated system Tasks and notifications
inTrayManager.sender=youremail@yourdomain.com inTrayManager.wctBaseUrl=${webapp.baseUrl}/Harvest Coordination
The harvestCoordinator is responsible for the coordination of harvest activity across all of the Harvest Agents. Defined in the Co-ordinator is the number of days before the Digital Asset Store is purged as well as the number of days before data remaining after aborted harvests is purged
harvestCoordinator.daysBeforeDASPurge=14 harvestCoordinator.daysBeforeAbortedTargetInstancePurge=7
The harvest coordinator is able to “optimize” harvests that are configured to be optimizable. Optimizable harvests will begin earlier than their scheduled time, when the harvests can support the extra harvest, and when the scheduled time is within the look-ahead window configuration. A number of harvesters can also be excluded from optimization, to allow for non-optimizable harvests to execute on schedule.
Targets can be configured as optimizable on the target edit screen.
harvestCoordinator.harvestOptimizationEnabled=true harvestCoordinator.harvestOptimizationLookaheadHours=12 harvestCoordinator.numHarvestersExcludedFromOptimisation=1
The harvestAgentFactory defines how many days in advance to generate future scheduled Target Instances
harvestAgentFactory.daysToSchedule=90
Group Search Controller
The groupSearchController defines how the default search is handled on the Groups tab. When defaultSearchOnAgencyOnly is set to true, the user name is omitted from the default Group search filter allowing the display of all groups for the current user’s agency. When defaultSearchOnAgencyOnly is set to false, the user name is included in the filter and only those Groups owned by the current user are displayed
groupSearchController.defaultSearchOnAgencyOnly=true
Archive Adapter
The archiveAdapter The archive adapter provides the mechanism for archiving a harvested target instance into an archive repository. When targetReferenceMandatory is set to true (or is omitted), the owning Target for a Target Instance being archived must have a Target Reference defined in order for archiving to be attempted. When targetReferenceMandatory is set to false, there is no need for the owning Target to have a Target Reference defined
archiveAdapter.targetReferenceMandatory=false
Quality Review Settings
The QualityReviewToolController settings control whether the standard browse tool, and external access tool, or both are available to the user. The ArchiveUrl setting specifies the location of the archive access tool, to allow the user to view copies of the target already stored in the archive. The ArchiveName is the name displayed on the review screen. The archive.alternative allows the use of a second review tool, with it’s corresponding name. The alternative can be commented out in the configuration if it is not required
qualityReviewToolController.enableBrowseTool=true qualityReviewToolController.enableAccessTool=false qualityReviewToolController.archiveUrl=http://web.archive.org/web/*/ qualityReviewToolController.archiveName=Wayback qualityReviewToolController.archive.alternative=http://web.archive.org/web/*/ qualityReviewToolController.archive.alternative.name=Another Wayback
The harvestResourceUrlMapper is responsible for writing the access tool URLs using a custom url and replacing elements of that url with the correct items in the harvest resource.
The urlMap property of the harvestResourceUrlMapper can have any of the following substituted value from the harvest resource
{$HarvestResource.Name} {$HarvestResource.Length} {$HarvestResource.Oid} {$HarvestResource.StatusCode} {$ArcHarvestResource.FileDate} {$HarvestResult.CreationDate[,DateFormat]} {$HarvestResult.DerivedFrom} {$HarvestResult.HarvestNumber} {$HarvestResult.Oid} {$HarvestResult.ProvenanceNote} {$HarvestResult.State}The HarvestResult.CreationDate substitution’s format can be controlled by supplying a valid simple date format after a comma within the curly brackets e.g. {$HarvestResult.CreationDate,ddMMyy } for 1 Nov 2008 will show “011108”
harvestResourceUrlMapper.urlMap=http://localhost:8090/wayback/{$ArcHarvestResource.FileDate}/{$HarvestResource.Name}The QualityReviewController.enableAccessTool and HarvestResourceUrlMapper settings can be used to allow Wayback to be used as an access tool for the WCT; either instead of, or in addition to the standard Browse tool. See Wayback Integration Guide.
Note, that if Wayback is being used as an access tool, the WaybackIndexer must be enabled and configured (see Digital Asset Store configuration below and Wayback Integration Guide.
Heritrix 3
Set the Heritrix major/minor version number that will be used with WCT. This version is displayed in the UI
heritrix.version=3.4.0
Set the directoy location of available H3 scripts. These scripts are available to users in the UI through the H3 scripting console. See Scripts directory under Setting up Heritrix 3
h3.scriptsDirectory=/usr/local/wct/h3scripts
The PolitenessOptions define the Heritrix 3 politeness settings. These values are shown in the UI when editing a Heritrix 3 profile, and are used to adjust whether a crawl will be performed in an aggressive, moderate or polite manner
crawlPoliteness.polite.delayFactor=10.0 crawlPoliteness.polite.minDelayMs=9000 crawlPoliteness.polite.MaxDelayMs=90000 crawlPoliteness.polite.respectCrawlDelayUpToSeconds=180 crawlPoliteness.polite.maxPerHostBandwidthUsageKbSec=400 crawlPoliteness.medium.delayFactor=5.0 crawlPoliteness.medium.minDelayMs=3000 crawlPoliteness.medium.MaxDelayMs=30000 crawlPoliteness.medium.respectCrawlDelayUpToSeconds=30 crawlPoliteness.medium.maxPerHostBandwidthUsageKbSec=800 crawlPoliteness.aggressive.delayFactor=1.0 crawlPoliteness.aggressive.minDelayMs=1000 crawlPoliteness.aggressive.MaxDelayMs=10000 crawlPoliteness.aggressive.respectCrawlDelayUpToSeconds=2 crawlPoliteness.aggressive.maxPerHostBandwidthUsageKbSec=2000
Core Base Directory
The core.base.dir defines a temporary working directory for harvest patching activities by the Webapp. The directory is used to store local files that have been imported into a harvest, as well as caching patching metadata.
core.base.dir=/usr/local/wct/webapp/
Triggers
The processScheduleTrigger defines when the heartbeat activity is checked on the registered Agents. The time is measured in milliseconds
processScheduleTrigger.startDelay=10000 processScheduleTrigger.repeatInterval=30000
Digital Asset Store - application.properties¶
The following are common configuration options for the DAS adjusted via the application.properties file.
DAS File Mover
The dasFileMover defines how the DAS will move harvest files from the temporary attachments directory to the DAS base storage directory
# For use when the DAS attachments directory is on a different filesystem than the store directory. arcDigitalAssetStoreService.dasFileMover=inputStreamDasFileMover # For use when the DAS attachments directory is on the same filesystem than the store directory. ##arcDigitalAssetStoreService.dasFileMover=renameDasFileMover
Additional Indexers
This section of the file allows configuration of additional indexers, which run concurrently with the standard WCT indexer. There are currently two additional indexers available (both disabled by default):
WaybackIndexer configures WCT to make copies of the ARC or WARC files and move them to the waybackInputFolder for automatic indexing by an installed Wayback instance. Wayback will eventually deposit a file of the same name in either the waybackMergedFolder (if successful) or the waybackFailedFolder (if unsuccessful). If useSymLinks is true the indexer will create symbolic (“soft”) links to the warc files instead of copies inside the waybackInputFolder to save space (default is false). The WaybackIndexer is disabled by default.
# Enable this indexer waybackIndexer.enabled=false # Frequency of checks on the merged folder (milliseconds) waybackIndexer.waittime=1000 # Time to wait for the file to be indexed before giving up (milliseconds) waybackIndexer.timeout=30000 # Location of the folder Wayback is watching for auto indexing waybackIndexer.waybackInputFolder=/usr/local/wct/wayback/store # Location of the folder where Wayback places merged indexes waybackIndexer.waybackMergedFolder=/usr/local/wct/wayback/index-data/merged # Location of the folder where Wayback places failed indexes waybackIndexer.waybackFailedFolder=/usr/local/wct/wayback/index-data/failed # Create soft links instead of copies inside waybackInputFolder to save space waybackIndexer.useSymLinks=false
CDXIndexer generates a CDX index file in the same folder as the ARC/WARC files. When a target instance is submitted to the archive, the CDX index will be copied along with the ARC/WARC file(s). The CDX format can be specified using the format variable. The default format is supported by the most commonly used tools. This indexer is enabled by default.
# CDXIndexer # Enable this indexer cdxIndexer.enabled=true # Set the cdx format (most common nowadays is the 11-field format: N b a m s k r M S V g) cdxIndexer.format=N b a m s k r M S V g
Archive Type
This section of the file specifies the location where Archives are stored on the file system. The Digital Asset store holds these files for a period of time before they are purged. See the Webapp configuration for the purge parameters.
arcDigitalAssetStoreService.archive=fileArchive
Using the File Archive Adapter (Default option)¶
The FileArchive writes files to a file system when they are archived. This directory should be permanent storage that is backed up, as these files are the definitive web archives that user wishes to store for prosperity.
# FileSystemArchive Adapter directory if using the File System Archive component
fileArchive.archiveRepository=/usr/local/wct/repository
# list of files added to the SIP for the File archive
fileArchive.archiveLogReportFiles=crawl.log,progress-statistics.log,local-errors.log,runtime-errors.log,uri-errors.log,hosts-report.txt,mimetype-report.txt,responsecode-report.txt,seeds-report.txt,processors-report.txt
fileArchive.archiveLogDirectory=logs
fileArchive.archiveReportDirectory=reports
fileArchive.archiveArcDirectory=arcs
Using other Archive Adapters¶
Other archive adapters may be specified by modifying the arcDigitalAssetStoreService.archive property. Current available types are fileArchive, omsArchive, dpsArchive.
For more information on dpsArchive, see Rosetta DPS Configuration Guide.
Harvest Agent - application.properties¶
The following are common configuration options for the Heritrix 3 Harvest Agent, adjusted via the application.properties file.
Harvest Agent Name
harvestAgent.name defines the visible name for the Harvest Agent, that is seen throughout the Webapp UI. All Harvest Agent names must be unique within a single Webapp instance.
harvestAgent.name=Local Agent H3
Concurrent Harvests
harvestAgent.maxHarvests defines the maximum number of concurrent harvests that a Harvest Agent can run. Take into account the available server resources when increasing this setting.
harvestAgent.maxHarvests=5
Harvest Recovery
The attemptHarvestRecovery is responsible for triggering a harvest recovery process in the Heritrix 3 Harvest Agent. This checks for running harvests in Webapp and Heritrix 3 and resumes them. This allows for restarting of the H3 Harvest Agent without orphaning the running jobs in Heritrix 3.
# whether to attempt to recover running harvests from H3 instance on startup. harvestAgent.attemptHarvestRecovery=true
Allowed Agencies
harvestAgent.allowedAgencies allows restricting of harvests belonging to specific Agencies within WCT. This can limit a Harvest Agent to users and crawls within a designated Agency.
# a comma separated list of WCT Agencies that are allowed to harvest with this Agent. # an empty list, allows any agency to harvest. harvestAgent.allowedAgencies=
System Checks
The three checker beans allow the Harvest Agent to monitor Disk, Processor and Memory. Each of the checkers are configurable to allow different alert and error thresholds. A Notification event will be sent on either the alert or error threshold being exceeded.
#MemoryChecker # The amount of memory in KB that can be used before a warning notification is sent memoryChecker.warnThreshold=512000 # The amount of memory in KB that can be used before an error notification is sent memoryChecker.errorThreshold=640000 #ProcessorCheck # The minimum percentage of processor available before a warning notification is sent processorCheck.warnThreshold=30 # The minimum percentage of processor available before an error notification is sent processorCheck.errorThreshold=20 #DiskSpaceChecker # the percentage of disk used before a warning notification is sent diskSpaceChecker.warnThreshold=80 # the percentage of disk used before an error notification is sent diskSpaceChecker.errorThreshold=90
Note, the processorCheck bean actually runs the following Unix command line utility to determine processor utilisation - (this command fails when running on Windows hosts);
"sar -u"
Setting up Heritrix 3¶
Integration with WCT¶
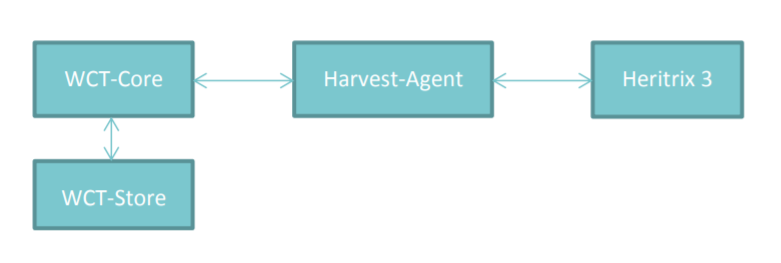
Heritrix 3 (H3) integrates with WCT through the H3 Harvest Agent. As an interface between the WCT Webapp and Heritrix 3, the Harvest Agent has three primary functions:
- actioning crawl commands from the WCT UI (start, stop, pause, abort).
- retrieving job status updates from Heritrix 3, to send onto Webapp.
- copying completed harvest files from Heritrix 3 job directory to the Digital Asset Store.
Heritrix 3 is a standalone application external from WCT.
The H3 Harvest Agent requires a corresponding Heritrix 3 instance to be running. If Heritrix 3 is not runnning then new Target Instances will fail to start crawling.
Prerequisites¶
Java - A minimum of Java 7 is required. However due to an https issue with H3, it is recommended to use Java 8.
For simplicity, it is recommended to run Heritrix 3 using the same Java version as WCT, which is now 64bit Java 8.
Download¶
Information on the latest stable versions of Heritrix 3 are available on Github and Maven Central.
The Heritrix 3 Github wiki contains a section detailing the current master builds available https://github.com/internetarchive/heritrix3/wiki#master-builds
For releases, see:
Building from source¶
Optionally, Heritrix 3 can be built from source. Use the Github repository: https://github.com/internetarchive/heritrix3/
Maven is required to build the project
The build of the Heritrix3 crawler is done from the directory that contains the cloned Heritrix3 github repository.
It’s recommended to skip the tests when building the Heritrix3 crawler as they can take a considerable amount of time to run (many minutes to hours).
mvn clean install -DskipTests=true
The build produces a heritrix-<heritrix-version>-SNAPSHOT-dist.zip in ./dist/target.
Unzip this zip in the parent folder of $HERITRIX_HOME.
Configuration¶
Location¶
It is recommended to run Heritrix 3 as close to it’s corresponding H3 Harvest Agent as possible, i.e. the same server. Running Heritrix 3 and the H3 Harvest Agent on separate servers has not been tested.
Memory¶
- If Heritrix 3 and it’s corresponding Harvest Agent are running on the same server as WCT Webapp and DAS, then Heritrix 3 may need greater memory allocation.
- Or depending on how many concurrent harvests you want to allow the H3 Harvest Agent to run, increasing the memory allocation for Heritrix 3 might be required.
Place the following lines near the top of heritrix-3.3.0/bin/heritrix
#Java Configuration
JAVA_OPTS=" -Xms256m -Xmx1024m"
Or set the JAVA_OPTS environment variable on the command line prior to running the Heritrix startup script:
export JAVA_OPTS=" -Xms256m -Xmx1024m"
Jobs directory¶
Heritrix 3 creates a folder in it’s job directory for each new job. After the registering
of a new job in Heritrix 3 by the H3 Harvest Agent, the Agent completes the initial setup
by copying the crawl profile (crawler-beans.cxml) and seeds (seeds.txt) into the
new job folder.
The system user running harvest-agent-h3.jar must have read and write access to the top level jobs directory (and any child job folders) for Heritrix 3.
On completion or termination of a Heritrix 3 job, the H3 Harvest Agent will attempt to clean up by removing the job folder.
The Heritrix 3 jobs directory must remain separate from the H3 Harvest Agent harvestAgent.baseHarvestDirectory. If the same directory is used, an empty profile will be given to Heritrix 3, causing a job to fail.
Scripts directory¶
The H3 scripts directory is used for storing pre-defined Heritrix 3 scripts (js, groovy, beanshell) that WCT makes available for use through the scripting console window. These scripts can be run against harvests running on Heritrix 3.
- The directory needs to be readable by the system user running WCT Webapp.
- The directory path needs to be set in application.properties inside Webapp.
For more information, please see:
Default profile¶
There are only a select group of Heritrix 3 profile settings available through the WCT UI to configure. If configuration of additional settings is required, then the default Heritrix 3 profile used by WCT can be edited. This is only recommened for advanced users.
The default profile is located in the project source:
webcurator-webapp/src/main/resources/defaultH3Profile.cxml
The Webapp component must be re-built to include any changes to the default profile.
If you don’t want to do a rebuild, you can edit the file in the webapp binary, which can be found here:
webcurator-webapp.war/WEB-INF/classes/defaultH3Profile.cxml
Care must be taken if editing the default profile xml. The WCT Heritrix 3 profile editor relies on a select group of xml elements being present and correctly formatted. The following list of xml elements must remain untouched in the xml. Other properties can be edited.
- Where properties are shown, WCT edits those values
- Where just the bean is shown, with no properties, WCT edits the entire bean element.
<bean id="metadata" class="org.archive.modules.CrawlMetadata" autowire="byName">
<!-- <property name="robotsPolicyName" value="obey"/> -->
<!-- <property name="userAgentTemplate" value="Mozilla/5.0 (compatible; heritrix/@VERSION@ +@OPERATOR_CONTACT_URL@)"/> -->
</bean>
...
<bean class="org.archive.modules.deciderules.TooManyHopsDecideRule">
<!-- <property name="maxHops" value="20" /> -->
</bean>
...
<bean class="org.archive.modules.deciderules.TransclusionDecideRule">
<!-- <property name="maxTransHops" value="2" /> -->
</bean>
...
<bean class="org.archive.modules.deciderules.TooManyPathSegmentsDecideRule">
<!-- <property name="maxPathDepth" value="20" /> -->
</bean>
...
<bean class="org.archive.modules.deciderules.MatchesListRegexDecideRule">
</bean>
...
<bean id="fetchHttp" class="org.archive.modules.fetcher.FetchHTTP">
<!-- <property name="defaultEncoding" value="ISO-8859-1" /> -->
<!-- <property name="ignoreCookies" value="false" /> -->
</bean>
...
<bean id="warcWriter" class="org.archive.modules.writer.WARCWriterProcessor">
<!-- <property name="compress" value="true" /> -->
<!-- <property name="prefix" value="IAH" /> -->
<!-- <property name="maxFileSizeBytes" value="1000000000" /> -->
</bean>
...
<bean id="crawlLimiter" class="org.archive.crawler.framework.CrawlLimitEnforcer">
<!-- <property name="maxBytesDownload" value="0" /> -->
<!-- <property name="maxDocumentsDownload" value="0" /> -->
<!-- <property name="maxTimeSeconds" value="0" /> -->
</bean>
...
<bean id="disposition" class="org.archive.crawler.postprocessor.DispositionProcessor">
<!-- <property name="delayFactor" value="5.0" /> -->
<!-- <property name="minDelayMs" value="3000" /> -->
<!-- <property name="respectCrawlDelayUpToSeconds" value="300" /> -->
<!-- <property name="maxDelayMs" value="30000" /> -->
<!-- <property name="maxPerHostBandwidthUsageKbSec" value="0" /> -->
</bean>
Proxy Access¶
Configuring Heritrix 3 for proxy access also requires editing of the default Heritrix 3 profile. Please refer to the preceding section for the details and caveats of editing the default profile.
To configure web proxy access the following properties in the fetchHTTP bean can configured:
<bean id="fetchHttp" class="org.archive.modules.fetcher.FetchHTTP">
<!-- <property name="httpProxyHost" value="" /> -->
<!-- <property name="httpProxyPort" value="0" /> -->
<!-- <property name="httpProxyUser" value="" /> -->
<!-- <property name="httpProxyPassword" value="" /> -->
</bean>
Running Heritrix 3¶
Credentials¶
By default the H3 Harvest Agent is configured to connect to H3 using:
- username: admin
- password: admin
If you wish to run H3 with different credentials, then update application.properties in harvest-agent-h3.jar to reflect that.
Starting Heritrix 3¶
- Linux/Unix
./heritrix-3.3.0/bin/heritrix -a admin:admin -j /mnt/wct-harvester/dev/heritrix3/jobs - Windows
./heritrix-3.3.0/bin/heritrix.cmd -a admin:admin -j /mnt/wct-harvester/dev/heritrix3/jobs
Stopping Heritrix 3¶
Heritrix 3 can be stopped using two methods:
- Via the UI. This will notify you of any jobs still running.
- Kill the Java process. It is your responsibility to check for and safely stop any running jobs.
Operation of Heritrix 3¶
Jobs¶
Two types of jobs are created in Heritrix 3 by the H3 Harvest Agent:
- Crawl Jobs - standard crawl jobs for WCT Target Instances. Created for the duration of running crawls.
- Profile Validation Jobs - a single re-used job to validate Heritrix 3 profiles created/edited in WCT-Core.
Heritrix management UI¶
Accessible locally via https://localhost:8443/engine
Logging¶
The Heritrix 3 application log is located in it’s base directory.
heritrix-3.3.0/heritrix_out.log
Additional notes¶
The Harvest Agent implementation for Heritrix 3 handles the creation and cleanup up of jobs within the Heritrix 3.x instance. You should only see job directories within Heritrix while a harvest is running or waiting to be completed. Once the harvest is complete and WCT has transferred the assets, logs and reports to the Store then the Heritrix job is torn down and directory deleted. The only occasions where a Heritrix job directory will not be cleaned up is if a job fails to build/start or an error has occurred during the harvest. This allows you to investigate the Heritrix job log to determine the cause.
Interacting with Heritrix 3 directly¶
Heritrix 3 can be operated directly (outside of WCT). Either use the UI or REST API to manually start a crawl.
Curl can be used to send actions to H3. See https://webarchive.jira.com/wiki/spaces/Heritrix/pages/5735014/Heritrix+3.x+API+Guide for details on how this is done.
Jobs won’t build or crawl¶
- Check the available logs. Investigate the crawl log to determine if H3 started to crawl the seed URLs.
- Is the seed.txt and crawler-beans.cxml being created in the harvest agent base directory, is it being transferred to the H3 job dir location?
- Check file permissions for job directory and seed.txt, crawler-beans.cxml files.
- Does the harvest profile contain a valid contact URL?
Old job dirs not being removed¶
Occasionaly there are nfs hidden files that prevent these folders from deleting fully. Make sure all hidden files are removed.
OpenSSL errors with Solaris and Java 7¶
If running on Solaris with Java 7 and you get openssl errors when the Harvest Agent tries to connect the Heritrix 3.x, try running Heritrix 3.x with Java 8.
Copying issues with larger harvests¶
If running Apache Tomcat with 32bit Java 7, you may experience issues with larger harvests copying between the Harvest Agent and the Store on completion of a crawl. This was resolved by running Apache Tomcat with 64bit Java 7.
Graceful shutdown and restart¶
The system can be taken down manually or automatically for maintenance.
To shut down and restart the Webapp and the DAS, but leave the harvesters running (so that they can continue harvesting when the Webapp and DAS are unavailable), follow these steps:
- Admin or script shuts down Webapp and DAS processes on server.
- Admin or script shuts down database.
- Admin or script does backup or required maintenance. WCT Harvest Agents continue harvesting.
- Admin or script starts database.
- Admin or script starts Webapp and DAS.
- WCT Harvest Agents re-register themselves with Webapp, and then copy any completed harvests to DAS and notify Webapp.
To shut down everything including the harvest agents, then the procedure is:
- Wait until all Harvest Agents have no crawl jobs running and shut them down. This can be best achieved by halting all Scheduled and Queued target instances using the ‘Calendar’ icon on the Harvester Configuration screen, and then waiting until the currently running jobs finish.
- Admin shuts down Webapp and DAS processes on server.
- Admin shuts down database.
Restart the system again in the reverse order.
Note, when you shut down a Harvest Agent, all running jobs are lost. If you pause a harvest then it stays in a paused state on the harvest agent, and is similarly lost when you shut down. These jobs can be successfully resumed via the harvest recovery process on startup, only if a crawl is still running in Heritrix 3.
Appendix A: Creating a truststore and importing a certificate¶
To create a truststore and import a certificate:
First export your public key from your Directory server.
- Refer to the documentation from your Directory server, in order to complete this task.
- If possible export the certificate as a binary file. We will assume your exported certificate is called mydirectorycert.der
Create a truststore and dummy key. Using the keytool provided with the java SDK:
keytool -genkey -dname "cn=dummy, ou=dummy, o=dummy, c=US" -alias dummy -keypass dummy -keystore /var/wctcore/ssl/wct.ts -storepass password
You need to import the X509 certificate for your directory server:
keytool -import -file mydirectorycert.der -keystore /var/wctcore/ssl/wct.ts
Appendix B: Example application.properties overrides¶
######################################
# Example WCT WebApp profile overrides
######################################
# Spring core settings
#####################################
# Cannot have the same port as anything else on the same host.
server.port=80
server.servlet.contextPath=/wct
# WebApp core settings
#####################################
# the host protocol type of Webapp
webapp.baseUrl=http://local-server.org.nz:${server.port}${server.servlet.contextPath}
#MailServer settings
mail.protocol=SMTP
mailServer.smtp.host=mailhost.org.nz
mail.smtp.port=25
#InTrayManager settings
inTrayManager.sender=wct-noreply@org.nz
#QualityReviewToolController settings
qualityReviewToolController.archiveUrl=http://local-server.org.nz:8080/wayback/*/
# HarvestResourceUrlMapper settings
harvestResourceUrlMapper.urlMap=http://local-server.org.nz:8080/wayback/{$ArcHarvestResource.FileDate}/{$HarvestResource.Name}
# Heritrix settings
#####################################
# Heritrix 3.x version
heritrix.version=3.4.0
# Name of the directory where the h3 scripts are stored
h3.scriptsDirectory=/mnt/wct-das/prod/h3scripts
# Digital Asset Store settings
#####################################
# the base service url of the digital asset store
digitalAssetStore.baseUrl=http://local-server.org.nz:8082
# the folder for transferring assets to the Digital Asset Store
digitalAssetStoreServer.uploadedFilesDir=/mnt/wct-das/prod/uploadedFiles/
# LDAP settings
#####################################
ldap.enable=true
ldap.url=ldap://library.org.nz:3268
ldap.usrSearchBase=dc=library,dc=org,dc=nz
ldap.usrSearchFilter=(sAMAccountName={0})
ldap.groupSearchBase=
ldap.groupSearchFilter=
ldap.contextSource.root=
ldap.contextSource.manager.dn=cn=LDAP Read, OU=Service Accounts,OU=Users,OU=Production,OU=Managed Objects,DC=library,DC=org,DC=nz
ldap.contextSource.managerPassword=XXXXXXXXXXXX
# Oracle Database Properties
## Database properties
databaseType=oracle
schema.name=DB_WCT
schema.url=jdbc:oracle:thin:@192.168.1.100:1521:wctprd01
schema.user=usr_wct
schema.password=XXXXXXX
schema.driver=oracle.jdbc.OracleDriver
schema.dialect=org.hibernate.dialect.Oracle12cDialect
schema.query=select 1 from dual
schema.maxIdle=5
schema.maxActive=10
schema.maxWait=5000
## Hibernate properties
hibernate.dialect=${schema.dialect}
hibernate.default_schema=${schema.name}
hibernate.show_sql=true
# must be set to true if you are using materialized_clob or materialized_blob properties
hibernate.jdbc.use_streams_for_binary=true
## Datasource
spring.datasource.name=jdbc/wctDatasource
spring.datasource.type=javax.sql.DataSource
spring.datasource.password=${schema.password}
spring.datasource.driver-class-name=${schema.driver}
spring.datasource.tomcat.max-idle=${schema.maxIdle}
spring.datasource.tomcat.max-wait=${schema.maxWait}
spring.datasource.tomcat.validation-query=${schema.query}
spring.datasource.username=${schema.user}
spring.datasource.url=${schema.url}
spring.datasource.tomcat.max-active=${schema.maxActive}
| [1] | Wayback refers to the Java version of the Wayback Machine originally from the Internet Archive. The current incarnation of Wayback is called OpenWayback and maintained by the IIPC. See https://github.com/iipc/openwayback |
| [2] | Wayback refers to the Java version of the Wayback Machine originally from the Internet Archive. The current incarnation of Wayback is called OpenWayback and maintained by the IIPC. See https://github.com/iipc/openwayback |